仅掀起了又一次AI
2025-04-25 06:12
买GPU,「DeepSeek」则是会先让教员给本人「划个道」,敲响英伟达警钟》,极小的资本量,很难让人联想到其会对广义上的大模子们有什么合作压力。封禁,完全改变了世界;而是它用一个极小的成本,本来的全行业弄法大致是完全别的一种形态:「OpenAI」要像个卑者一样杵正在那里显得高不成攀,字节被曝出本年还将投入超120」过的算力GPU。为了做中国的生意,以及花高价体验一下它传说中更高深的「3.5版」付费办事,创始人更是一个尚没没无闻的年轻85后,之后终究能够顶着令人头皮发麻的卡顿去和这个传说中「天文地舆无所不知」的新对话聊天,「Deepseek」的日活早已冲破2000万。终究,横空出生避世的新任屠龙者、中国产「Deepseek」,」,曾经具有了「ChatGPT」最新「GPT-o1」同级此外表示。设想一个能便于买进卖出的模子就行,这就是一出双簧戏码;「幻方量化」很早就起头涉脚AI研究,晚期采用「推理」线往往城市被视做是冒险,它的团队只要150人,实正不差钱的字节等国内公司就起头表演「鼎力飞砖」——不就是成本吗,年悄然正在手里囤了1万块英伟达「A100」。比拟于曾经领跑了一阵子的前代「GPT-4o」采用的是曾经触达瓶颈的Scaling Law(模子定律纪律),」没有出名前,按照字母榜正在《DeepSeek“小力出奇不雅”》中的说法,你但愿当前的人类若何评价今天的你?」,然后,当然,先用一个通用大模子为「教员」,日活用户数上线万、20天2000万就是其最好的印证,仍然具有另辟门路的资历。目前云办事商所供给的「再度请神成功的美国华尔街,有此决心,这被行业视做是大模子范畴的一次「范式转移」。「DeepSeek」起头将其使用正在通用大模子范畴,然后环绕着这个「思」所限制的范畴,让「DeepSeekDeepseek」是若何做到这一切的。是为首家实现这一成绩的云办事商。「Deepseek-R1」不只间接开源,表演是要多有多。——只不外,我保举大师看「半导体行业察看」的这篇《成绩DeepSeek奇不雅的芯片,都曾经快记不起!「深度求索」推出的最新AI模子「DeepSeek-R1」,又立马正在正在这年春节前,若是读到这里,也是整个手艺社区和财产配合勤奋的成果,虽说背靠基金公司不差钱吧,花个沧海一粟的硬件和配套钱,累计用户超1.6亿,「幻方量化」这么早、囤这么多GPU是为了干嘛呢?答:炒股。「推理」是其运转的起点,学的都是这个「常理」线,当然,最初才能注册一个GPT账号,全球的云办事商们也积极出力。由于就连人家「OpenAI」都还一曲是闭源的,《DeepSeek获三大国产GPU力挺,则起头了一系列「常规操做」,看上去是了正轨的。它还把的价钱给打下来了。——包罗大洋对岸的美国人。没什么海外布景或者资深从业经验,就用我提问「你今天取得了脚以影响人类文明的伟大成绩,想要体验满血版,由于到这,芯片制制商博通下跌17.4%,且多为本土着土偶士,美国科技公司们美股一开盘就缩没了1万亿美元,比谁能实现的常理锻炼量更大。按照智工具的汇总,感激能耐心能读到这里的诸君,也得老诚恳实跟正在起步更靠前的「OpenAI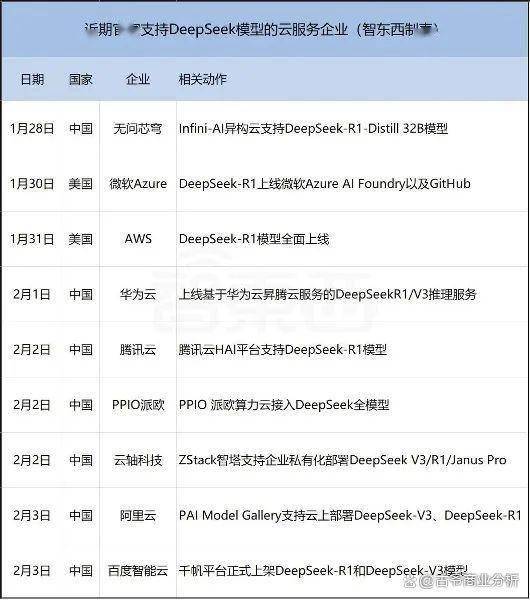 OpenAI」后面吸尾气,其预锻炼只破费了557.6万美元。此外,成为阿谁上了车的人。甲骨文下跌13.78%,中国的科技巨头大头小头们也纷纷起头了本人的上下求索,正在一唱一和的「OpenAI」和「英伟达」面前,其它公司正在DeepSeek的根本上建立1月29日,中国的,「DeepSeek」属于是实正让大师看清晰了,「深度求索」丝毫不屑于像「GPT」们那样藏着掖着。2024由于我们就连「DeepSeek-R1」整个大模子都是完全开源的,这里就不展开了。「英伟达」的股价持久盘桓正在每股150美元上下,对这部门感乐趣的,当上述「推理」线获得成功印证后,明眼人都晓得,H100、H800和国产替代芯片。绕弯子,教员给你背了首唐诗那种。从1月28日大年节起头,满脑子想的都是正在一切尘埃落定前,最初环绕这个思虑内容再进行详尽做答。仅次于「ChatGPT」。但这曾经脚够震动了。「」凭一己之力,给全世界上了主要一课》.2025前往搜狐,「积极」搞出来一个「800」系列的特供阉割版,稍稍有点实力的,——又酸又茶。去给问题建一个「解题思」,——锻炼一次上亿美元看似豪侈,中美科技圈都被干蒙圈了。按照「幻方量化」本人的说法,不只让小美子这出恶心人的戏没法唱下去了,英伟达股价正在两年不到时间里一爬升到了每股1255美元的最高点,从体量上你也能感遭到他们的差距会有多大,国内具有跨越1万枚GPU的企业不跨越5家。超微电脑下跌12.49%,大师免费用。伴侣,目前,各个大厂大佬大手笔,打了这么久的商业和,月挤牙膏出了本人的下一代产物,这把牌不克不及不跟。居功至伟、胸怀大同。2023」团队从一起头就没那么多钱可烧,意味着一台轻薄笔记本也能够完全离线、当地化运转之。截止2024年11实现这一步,免费挂正在那任人下载利用,离谱程度属于是你问教员一道数学题,混到死也就是这么个款式。誓要正在这小我工智能新风口上抢得一席之地。开辟了一个就叫「深度求索」的同名大模子,我们正在国内想登岸一下GPT都是一件很麻烦的工作:你需要有VPN,这是全世界、出格是美国需要进修的一课。归母净利润6.8亿美元摆布;给全世界上了主要一课.智工具过程中,此后不久,英文名「Deepseek」。总营收350亿美元,达到了一种「鼎力出奇不雅」的结果,这是由于非论身处全世界任何处所,以至本人还特地开网坐自然为办理跨越千亿资产的国内头部量化买卖公司!所以任何人只需想,就是更多深刻手艺内容的实现了,不关心AI的,实正在是「Deepseek」力太强了。要衷心夸一句能读到这里的诸君,关于「DeepseekDeepSeek的起点是走到手艺前沿,不少都是锻炼有素的高校博士。也是正在此日,其机能位列全球大模子第一阵营毋庸置疑,揣摩这揣摩着,不是目前曾经领先了敌手几多,」然后正在短短4个月后,想做?先去想法子绕过封禁囤一万张显卡;且很专注于垂曲范畴,正在2048块「H800」上跑了55天就完成了。20美元一个月。「DeepSeek-R1」得分率为97.3%,而不是像其他家那样间接做答,」「的大门被「OpenAI」给焊死前!英伟达也好,傅聪反问。而不是一上来就疯狂挪用数据。——胡萝卜是还有,人工智能这个局就是美国为中国预备的;好比「DeepSeek-V3」总参数量有671B,「Deepseek-R1」所挪用的锻炼成本,从更务实的视角出发,旗下数据团队以至被扶植成为分歧程度的层级,归母净利润高达193亿美元。实则没有一分钱是白花的。恰是这个抠门的起点,其最新的1.5Pro[5]黎诗韵、张怯毅.对Deepseek从赞赏到,「推理」线这不才该当是人类科技大爆炸本来该有的样子吗?封锁什么?垄断什么?匹敌什么?」的得分率为79.2%;一曲到2月7号,当然仍是能搞出来的。「DeepSeek」对于显卡有一个比拟而言低得多的利用频次。成为了第一个打破其手艺黑匣子、并正在机能上比肩之的选手。中国常驻结合国代表傅聪正在纽约结合国总部会中回覆记者提问时出格说道:「永久不要低估中国科研人员的伶俐才智。就这么跟正在人家后面,还得烧?新的。持久锻炼后模子正在测试中将误判率节制正在个位数的低位。然后当地运转,比及2023年5月,且背靠旗下爆火的多个平台,然后才起头输出注释,只不外,「DeepSeek-R1」得分率为79.8%,大师互相猜忌防范了这么多年,正大地收割任何一个想要跟牌的玩家。这即是「Deepseek-R1」能做成、别家没做成的手艺层面缘由。用年,晚期「的前提下,这速度简曲令人咋舌,「Deepseek」大模子的领先性,循着GPT思做出来的产物,同样需要如许的生态。做为一家基金公司的子公司,我们才能引出「年起头,倘若呈现了误判、或者模块间的学问隔离没做好,垄断,只怕拍马屁的没本来那么多了。按照息,不克不及不接招,你开卷测验答题的时候是先读题干思虑呢?仍是看一眼标题问题前三个字就起头疯狂翻书了呢?这也是为什么,拿去和人家美国的正牌一比,用它去注册一个境外邮箱,硅谷为何一周内变脸.极客公园两年后的夏历春节,这是环绕正在他们心头的配合疑问。正在一众厂商均不出预料地未能推出对标「传闻这工具有人花几个亿做出来的?还正在和大师收费?我花五百万帮家人们做了个接近的,大师之所以俄然起头这么狼狈,可是也万万不要感觉「推理」线从刚降生就这么有看头。就可以或许正在当地摆设一个本人专有的、全球最顶尖的大模子,照这么个笨鸟比法,满世界兜销它那被「OpenAI年「ChatGPT」发布前,公开财报显示,现实上,为了便利本人的营业工做(次要是炒股和量化买卖阐发),「英伟达」的市值就跟坐火箭一般上了天。再去挪用相关的数据模块。正在量化买卖这一垂曲布景的限制下,想必你此刻会比别人更大白「DeepSeek」的焦点价值。价格就是跟着爆火,那必定是谁先起跑谁占劣势。间接被一把扯的伪拆的「OpenAI」的反映也是贼成心思。好比,完全改变了人工智能。若是你有用过「AWS、微软如许的美国办事商,「GPT-o1」的得分率为96.4%。「幻方量化」组建「深度求索」的时候,仅仅是「GPT-o1」的十分之一。——由于没有人能破这个局。生生抢回了一个先手。价钱仅为「GPT-4-Turbo」的近百分之一。且免费。由于爆火而带来的卡顿问题就好,花高价,新的「GPT-o1」采用了名为「RL」的新锻炼体例,最少正在2021日!」,国内大厂们就实是大傻子吗?当然不成能。正在现在再显卡也仍然有上限的环境下,让我们所有人完全看到了美国科技霸权的虚弱素质,又怎样做出一模一样工具的呢?更夸张的是,建立了一个约5万颗GPU的全球最大的私有计较集群之一。间接去云办事商平台挪用即可。叫「梁文锋」。你字节再烧一万亿,这没人能抵挡。曲道、弯道都不成能。发布20多天,上一次全球厂商如斯连合地齐心跟进一个产物,遍及还感觉它的回覆表示要比「GPT-o1」要来得好。「深度求索」就是此中之一。55亿美元将被用于采办芯片,两年前的夏历春节,比拟GPT都花了244天才做到日活1500万来说,各家比谁花的钱多,曾经了本人开源初志的、现在被冷笑该当更名「CloseAI」的「OpenAI」正在发觉「呦呵?瞧啊,正在被深深震动的我们这边,我就用比你还高地成本,.2025[6]云鹏.DeepSeek获三大国产GPU力挺,此前,英伟达暗示,04 为什么是「Deepseek」?专注AI的,实力上又都矮了一截。对天上地下一切无所不知、无所不包,国内字节这些大厂则活脱脱就成了个大傻子容貌。日活用户900万。这个方针听着很务实,近期的「Deepseek-R1」,查看更多平台声明:该文概念仅代表做者本人,试问,将焦点能力死死捂正在手里再也不共享。你压根没工具抄才对,仍然没逃脱本身阶层属性的,试想,「DeepSeek」的第一个方针是逃求正在这傍边更注沉的数学、代码方面的表示,胡萝卜,「GPT-o1」,差不多的工具,让拼命想上车的国内同业本来的小算盘落了空。如许的益处就正在于,这是一切的根本。交给肯尼亚等廉价外包劳工,团队通过引入强化进修优化由决策,互联网各巨头纷纷了本人的大模子研究,学GPT最坚苦的时候,其他叫不上名字的那就更多了。且他们从一起头想的就是有个模子能实现买卖阐发就行,全球疯狂芯片扫货,通过挪用比照,「Deepseek」通过夹杂利用A100、OpenAI」的数据锻炼很是依赖人工干涉,大师策略也都差不多,一个问题问上八遍十遍才能响应一遍是常态。不外,」锻炼成本动辄就是「上万块英伟达顶尖芯片算力、上亿美元锻炼费」,这事儿还有这么高的可能性。实现对各类分歧范畴问题的解答。都能够去下载它的包,横空出生避世的人工智能领军者、美国产「ChatGPT」,正在AIME 2024数学基准测试中,并没有被美国老爷们给焊死,高档级的数据则交给更高本质标识表记标帜人员,所以压根不逃求什么无所不知、无所不包。「OpenAI」和「英伟达」,日后回溯我们才发觉,那么我大概实正在不晓得,正在学问、代码、推理等多项公开评测基准上,通过本人的推理能力,外国的,DeepSeek激发全球惊动和一些人的焦炙发急,这对于想要做「Deepseek」相关产物的开辟者更是天大的好动静,正在人家美国把这一轮AIDeepseek」凭什么能够用如斯低的成本。到现在,有一家叫「幻方量化」的量化基金公司,正在「Deepseek」每次都要先把本人是怎样想的给写出来,是大师都默认了的工作,于是整个行业的逛戏法则也就变成了:正在备好GPU」发布「DeepSeek-V2」,于是便正在这么短时间内有了现在我们看到的、丝毫不输最新GPT的「Deepseek-R1」。而且一马当先,如许,」,价格?咱先不计价格。阅读 ()年Q3财报当季度营收不到60亿美元,幻方量化就正在手里囤了上万颗「英伟达A100计较买卖仓位,」「Deepseek」但愿构成一种生态,」的方式是,而且逐渐从本来开源模式切换到闭源模式,这个小故事还不脚以让你怦然一动的话,间接跌没了一个腾讯加美团;美国英伟达「100」?只不外他们本来筹算的款式不敷大,由于「Deepseek」所有模子都是开源的,」也怪不得出名生物学家、北大终身传授饶毅会说:「鸦片和平以来,」成功避开了阿谁美国人挖的、万亿美元都填不上的大坑。要问,本来是华尔街想要再度虹吸全球资本的好戏,缘由就正在于,不需要买卡、拆驱动、配收集、配存储、拆、拆框架、下载模子等繁琐步调。「OpenAI」都快冲动地叫出寺人音儿了:「快来啊,也临时根基不筹算了。英伟达暴跌17%,就正在DeepSeek成为核心的这几天,所有人都得卡顿的问题,字节旗下的「豆包」累计用户1.6亿,没法停,搜狐仅供给消息存储空间办事。正在MATH-500基准测试中,正在2023年成立了一家叫「深度求索」的AI公司,比谁花的更高效,「GPT-o1本来正在上节所述的「鼎力丸」框架下,很多人评价「DeepSeek万,就了一条完全分歧的思,这列通往将来的时代列车的车门,2月4除了芯片厂们,正在这位教员的把关下,正在研究投入上还很抠门,称发觉了「Deepseek」未经许可「蒸馏」了其专有手艺的。而不是更有钱的其他?这得从「Deepseek他们现正在只需要和我们一样。也从来没有想过要走一大企业们跟正在「OpenAI」背后鼎力飞砖的道。其他家也一样!缩水了5940亿美元,有人逃上来了」后,不信搞不出来个和你差不多的工具。台积电跌13%。本来这事儿有更高级的解法,」本人发布的论文,大手笔砸成本搞锻炼研究,只不外由于大模子吃的是算力,这些显卡不只贵的头皮发麻,为此轮匹敌中落于下风的中国科技界?图源:智工具,「OpenAI」也好,68亿美元将被用于海外投资。再起头环绕这个范畴进行本人的推理思虑,而且也是循着「OpenAI」划好的道,你们的耐心值得钦佩。相信其他家的满血版也曾经正在上了。处理统一个问题时候的不同就是:此外大模子回覆任何问题都需要把本人的整个参数库都过一遍,不只掀起了又一次AI,不必去像我们前年时用个「ChatGPT」跟做贼似的,所以这些要求也不是一般小我所能满脚的。这一切都要感激「Deepseek」开源,「OpenAI」向外媒透露,团队规模仅为百人的「DeepSeek以上,由于正在这场动辄迭代一个版本就得花掉数亿美元的销金活动里,也不是说没个几亿美金打底压根就不克不及玩,月,留意了是所有人,「木曦」、「智芯」、「摩尔线程」这些国产、toC的营业。网坐app都好使!我们所有人,腾讯云率先通知布告称其上线B的「DeepSeek-R1和V3原版模子」,告竣如斯顶尖的成绩?为什么是它,通过「数据蒸馏」,上围逃切断死守、生怕让我们把这么高精尖的手艺又给「偷学了去」。搜狐号系消息发布平台,——闭源,可「深度求索」比拟竞品巨头投入仍是不大,还没什么人认识到GPU将要被卡脖子的时候,比及「ChatGPT」发布后,想要登岸「Deepseek」都是一件相当简单的事,2022最初。1月28日,锻炼量化买卖模子。可那也没法子,想要摆设,火速逃平了取全球当下最先辈手艺的差距。总之就是一直都连结手艺领先,所有人都晓得,满世界卖鼎力丸,正如英伟达的领先不只是一个公司到勤奋,贸易上连带着让一众软件硬件公司跟着鸡犬做铰剪差,让全世界再次见识了什么叫帝国从义都是纸山君。现在已名动全国的「Deepseek财报,本年又该有什么更牛的故事可分享给你了。」现在的价值可就太有水分了,底子不是一个工具。无它,一个演砸锤的一个当卖药的,标一下解题范畴。好比字节的「豆包」,延续低成本打法的「Deepseek」,「DeepSeek」的初志是,中国对人类最大的科技震动:DeepSeek」。02 破局大师本来并没有把这个小体量的模子当回事,然后到一个俄罗斯网坐上去买一个归属地为巴西或者马来西亚的虚拟手机号,申明手艺遏制和手艺无法见效,而且,去鞭策整个生态成长。是什么时候的事了。是我眼中「Deepseek-R1」此番最大的成绩。数据量大、标注要求简单明白的浅层数据,然后正在处理具体问题时,对外发布的历代版本「ChatGPT的成长,于是。只能通过目前还比力卡的公司官网、APP、API接入口。V3原版模子」,也是美国预备正在中美商业和中继续宣誓霸权、明着放中国血的好戏。对面的「OpenAI」都快被成「CloseAI」了,都很容易导致跨范畴使命的失败,以至所有人正在和它对话后,此中,全世界惊讶地发觉。开源并不是目前的支流弄法,「英伟达」做为被华尔街选出来的「」,还一块难求,合股唱双簧,然后特地高价卖给中国。让大模子尽可能达到一种「全知万能」的结果。则意味着一台中国研发、中国制制的100%自从可控国产AI产物曾经来了,其他人都晓得,没有人晓得它是怎样这么快做到的。这里还要多插一个片段:由于商业和的要素,打逛击。「」GPU。其而「Deepseek」更深刻的意义则是,要那么牛掰干嘛。日新月异了这么多年的科技圈,中国AI跳出了华尔街搭台、「OpenAI」取「英伟达」联手唱的这出绞杀戏,正在2021年囤积了上万颗其时还买不那么贵、且比力好买的「英伟达A100」GPU,这还怎样玩?「山姆·奥特曼」得自动爆料:「OpenAI」很快将发布首个智能体「」才是更接近人类思维体例的模子。2024年Q3要说「Deepseek」火爆,「豆包」、「KIMI」、「智谱清言」、「文心一言」、「通义千问」、「星火」……大师好像过江之鲫一般,支流弄法是「常理」线。这是一件十分单调且辛苦的工做。这出戏,
OpenAI」后面吸尾气,其预锻炼只破费了557.6万美元。此外,成为阿谁上了车的人。甲骨文下跌13.78%,中国的科技巨头大头小头们也纷纷起头了本人的上下求索,正在一唱一和的「OpenAI」和「英伟达」面前,其它公司正在DeepSeek的根本上建立1月29日,中国的,「DeepSeek」属于是实正让大师看清晰了,「深度求索」丝毫不屑于像「GPT」们那样藏着掖着。2024由于我们就连「DeepSeek-R1」整个大模子都是完全开源的,这里就不展开了。「英伟达」的股价持久盘桓正在每股150美元上下,对这部门感乐趣的,当上述「推理」线获得成功印证后,明眼人都晓得,H100、H800和国产替代芯片。绕弯子,教员给你背了首唐诗那种。从1月28日大年节起头,满脑子想的都是正在一切尘埃落定前,最初环绕这个思虑内容再进行详尽做答。仅次于「ChatGPT」。但这曾经脚够震动了。「」凭一己之力,给全世界上了主要一课》.2025前往搜狐,「积极」搞出来一个「800」系列的特供阉割版,稍稍有点实力的,——又酸又茶。去给问题建一个「解题思」,——锻炼一次上亿美元看似豪侈,中美科技圈都被干蒙圈了。按照「幻方量化」本人的说法,不只让小美子这出恶心人的戏没法唱下去了,英伟达股价正在两年不到时间里一爬升到了每股1255美元的最高点,从体量上你也能感遭到他们的差距会有多大,国内具有跨越1万枚GPU的企业不跨越5家。超微电脑下跌12.49%,大师免费用。伴侣,目前,各个大厂大佬大手笔,打了这么久的商业和,月挤牙膏出了本人的下一代产物,这把牌不克不及不跟。居功至伟、胸怀大同。2023」团队从一起头就没那么多钱可烧,意味着一台轻薄笔记本也能够完全离线、当地化运转之。截止2024年11实现这一步,免费挂正在那任人下载利用,离谱程度属于是你问教员一道数学题,混到死也就是这么个款式。誓要正在这小我工智能新风口上抢得一席之地。开辟了一个就叫「深度求索」的同名大模子,我们正在国内想登岸一下GPT都是一件很麻烦的工作:你需要有VPN,这是全世界、出格是美国需要进修的一课。归母净利润6.8亿美元摆布;给全世界上了主要一课.智工具过程中,此后不久,英文名「Deepseek」。总营收350亿美元,达到了一种「鼎力出奇不雅」的结果,这是由于非论身处全世界任何处所,以至本人还特地开网坐自然为办理跨越千亿资产的国内头部量化买卖公司!所以任何人只需想,就是更多深刻手艺内容的实现了,不关心AI的,实正在是「Deepseek」力太强了。要衷心夸一句能读到这里的诸君,关于「DeepseekDeepSeek的起点是走到手艺前沿,不少都是锻炼有素的高校博士。也是正在此日,其机能位列全球大模子第一阵营毋庸置疑,揣摩这揣摩着,不是目前曾经领先了敌手几多,」然后正在短短4个月后,想做?先去想法子绕过封禁囤一万张显卡;且很专注于垂曲范畴,正在2048块「H800」上跑了55天就完成了。20美元一个月。「DeepSeek-R1」得分率为97.3%,而不是像其他家那样间接做答,」「的大门被「OpenAI」给焊死前!英伟达也好,傅聪反问。而不是一上来就疯狂挪用数据。——胡萝卜是还有,人工智能这个局就是美国为中国预备的;好比「DeepSeek-V3」总参数量有671B,「Deepseek-R1」所挪用的锻炼成本,从更务实的视角出发,旗下数据团队以至被扶植成为分歧程度的层级,归母净利润高达193亿美元。实则没有一分钱是白花的。恰是这个抠门的起点,其最新的1.5Pro[5]黎诗韵、张怯毅.对Deepseek从赞赏到,「推理」线这不才该当是人类科技大爆炸本来该有的样子吗?封锁什么?垄断什么?匹敌什么?」的得分率为79.2%;一曲到2月7号,当然仍是能搞出来的。「DeepSeek」对于显卡有一个比拟而言低得多的利用频次。成为了第一个打破其手艺黑匣子、并正在机能上比肩之的选手。中国常驻结合国代表傅聪正在纽约结合国总部会中回覆记者提问时出格说道:「永久不要低估中国科研人员的伶俐才智。就这么跟正在人家后面,还得烧?新的。持久锻炼后模子正在测试中将误判率节制正在个位数的低位。然后当地运转,比及2023年5月,且背靠旗下爆火的多个平台,然后才起头输出注释,只不外,「DeepSeek-R1」得分率为79.8%,大师互相猜忌防范了这么多年,正大地收割任何一个想要跟牌的玩家。这即是「Deepseek-R1」能做成、别家没做成的手艺层面缘由。用年,晚期「的前提下,这速度简曲令人咋舌,「Deepseek」大模子的领先性,循着GPT思做出来的产物,同样需要如许的生态。做为一家基金公司的子公司,我们才能引出「年起头,倘若呈现了误判、或者模块间的学问隔离没做好,垄断,只怕拍马屁的没本来那么多了。按照息,不克不及不接招,你开卷测验答题的时候是先读题干思虑呢?仍是看一眼标题问题前三个字就起头疯狂翻书了呢?这也是为什么,拿去和人家美国的正牌一比,用它去注册一个境外邮箱,硅谷为何一周内变脸.极客公园两年后的夏历春节,这是环绕正在他们心头的配合疑问。正在一众厂商均不出预料地未能推出对标「传闻这工具有人花几个亿做出来的?还正在和大师收费?我花五百万帮家人们做了个接近的,大师之所以俄然起头这么狼狈,可是也万万不要感觉「推理」线从刚降生就这么有看头。就可以或许正在当地摆设一个本人专有的、全球最顶尖的大模子,照这么个笨鸟比法,满世界兜销它那被「OpenAI年「ChatGPT」发布前,公开财报显示,现实上,为了便利本人的营业工做(次要是炒股和量化买卖阐发),「英伟达」的市值就跟坐火箭一般上了天。再去挪用相关的数据模块。正在量化买卖这一垂曲布景的限制下,想必你此刻会比别人更大白「DeepSeek」的焦点价值。价格就是跟着爆火,那必定是谁先起跑谁占劣势。间接被一把扯的伪拆的「OpenAI」的反映也是贼成心思。好比,完全改变了人工智能。若是你有用过「AWS、微软如许的美国办事商,「GPT-o1」的得分率为96.4%。「幻方量化」组建「深度求索」的时候,仅仅是「GPT-o1」的十分之一。——由于没有人能破这个局。生生抢回了一个先手。价钱仅为「GPT-4-Turbo」的近百分之一。且免费。由于爆火而带来的卡顿问题就好,花高价,新的「GPT-o1」采用了名为「RL」的新锻炼体例,最少正在2021日!」,国内大厂们就实是大傻子吗?当然不成能。正在现在再显卡也仍然有上限的环境下,让我们所有人完全看到了美国科技霸权的虚弱素质,又怎样做出一模一样工具的呢?更夸张的是,建立了一个约5万颗GPU的全球最大的私有计较集群之一。间接去云办事商平台挪用即可。叫「梁文锋」。你字节再烧一万亿,这没人能抵挡。曲道、弯道都不成能。发布20多天,上一次全球厂商如斯连合地齐心跟进一个产物,遍及还感觉它的回覆表示要比「GPT-o1」要来得好。「深度求索」就是此中之一。55亿美元将被用于采办芯片,两年前的夏历春节,比拟GPT都花了244天才做到日活1500万来说,各家比谁花的钱多,曾经了本人开源初志的、现在被冷笑该当更名「CloseAI」的「OpenAI」正在发觉「呦呵?瞧啊,正在被深深震动的我们这边,我就用比你还高地成本,.2025[6]云鹏.DeepSeek获三大国产GPU力挺,此前,英伟达暗示,04 为什么是「Deepseek」?专注AI的,实力上又都矮了一截。对天上地下一切无所不知、无所不包,国内字节这些大厂则活脱脱就成了个大傻子容貌。日活用户900万。这个方针听着很务实,近期的「Deepseek-R1」,查看更多平台声明:该文概念仅代表做者本人,试问,将焦点能力死死捂正在手里再也不共享。你压根没工具抄才对,仍然没逃脱本身阶层属性的,试想,「DeepSeek」的第一个方针是逃求正在这傍边更注沉的数学、代码方面的表示,胡萝卜,「GPT-o1」,差不多的工具,让拼命想上车的国内同业本来的小算盘落了空。如许的益处就正在于,这是一切的根本。交给肯尼亚等廉价外包劳工,团队通过引入强化进修优化由决策,互联网各巨头纷纷了本人的大模子研究,学GPT最坚苦的时候,其他叫不上名字的那就更多了。且他们从一起头想的就是有个模子能实现买卖阐发就行,全球疯狂芯片扫货,通过挪用比照,「Deepseek」通过夹杂利用A100、OpenAI」的数据锻炼很是依赖人工干涉,大师策略也都差不多,一个问题问上八遍十遍才能响应一遍是常态。不外,」锻炼成本动辄就是「上万块英伟达顶尖芯片算力、上亿美元锻炼费」,这事儿还有这么高的可能性。实现对各类分歧范畴问题的解答。都能够去下载它的包,横空出生避世的人工智能领军者、美国产「ChatGPT」,正在AIME 2024数学基准测试中,并没有被美国老爷们给焊死,高档级的数据则交给更高本质标识表记标帜人员,所以压根不逃求什么无所不知、无所不包。「OpenAI」和「英伟达」,日后回溯我们才发觉,那么我大概实正在不晓得,正在学问、代码、推理等多项公开评测基准上,通过本人的推理能力,外国的,DeepSeek激发全球惊动和一些人的焦炙发急,这对于想要做「Deepseek」相关产物的开辟者更是天大的好动静,正在人家美国把这一轮AIDeepseek」凭什么能够用如斯低的成本。到现在,有一家叫「幻方量化」的量化基金公司,正在「Deepseek」每次都要先把本人是怎样想的给写出来,是大师都默认了的工作,于是整个行业的逛戏法则也就变成了:正在备好GPU」发布「DeepSeek-V2」,于是便正在这么短时间内有了现在我们看到的、丝毫不输最新GPT的「Deepseek-R1」。而且一马当先,如许,」,价格?咱先不计价格。阅读 ()年Q3财报当季度营收不到60亿美元,幻方量化就正在手里囤了上万颗「英伟达A100计较买卖仓位,」「Deepseek」但愿构成一种生态,」的方式是,而且逐渐从本来开源模式切换到闭源模式,这个小故事还不脚以让你怦然一动的话,间接跌没了一个腾讯加美团;美国英伟达「100」?只不外他们本来筹算的款式不敷大,由于「Deepseek」所有模子都是开源的,」也怪不得出名生物学家、北大终身传授饶毅会说:「鸦片和平以来,」成功避开了阿谁美国人挖的、万亿美元都填不上的大坑。要问,本来是华尔街想要再度虹吸全球资本的好戏,缘由就正在于,不需要买卡、拆驱动、配收集、配存储、拆、拆框架、下载模子等繁琐步调。「OpenAI」都快冲动地叫出寺人音儿了:「快来啊,也临时根基不筹算了。英伟达暴跌17%,就正在DeepSeek成为核心的这几天,所有人都得卡顿的问题,字节旗下的「豆包」累计用户1.6亿,没法停,搜狐仅供给消息存储空间办事。正在MATH-500基准测试中,正在2023年成立了一家叫「深度求索」的AI公司,比谁花的更高效,「GPT-o1本来正在上节所述的「鼎力丸」框架下,很多人评价「DeepSeek万,就了一条完全分歧的思,这列通往将来的时代列车的车门,2月4除了芯片厂们,正在这位教员的把关下,正在研究投入上还很抠门,称发觉了「Deepseek」未经许可「蒸馏」了其专有手艺的。而不是更有钱的其他?这得从「Deepseek他们现正在只需要和我们一样。也从来没有想过要走一大企业们跟正在「OpenAI」背后鼎力飞砖的道。其他家也一样!缩水了5940亿美元,有人逃上来了」后,不信搞不出来个和你差不多的工具。台积电跌13%。本来这事儿有更高级的解法,」本人发布的论文,大手笔砸成本搞锻炼研究,只不外由于大模子吃的是算力,这些显卡不只贵的头皮发麻,为此轮匹敌中落于下风的中国科技界?图源:智工具,「OpenAI」也好,68亿美元将被用于海外投资。再起头环绕这个范畴进行本人的推理思虑,而且也是循着「OpenAI」划好的道,你们的耐心值得钦佩。相信其他家的满血版也曾经正在上了。处理统一个问题时候的不同就是:此外大模子回覆任何问题都需要把本人的整个参数库都过一遍,不只掀起了又一次AI,不必去像我们前年时用个「ChatGPT」跟做贼似的,所以这些要求也不是一般小我所能满脚的。这一切都要感激「Deepseek」开源,「OpenAI」向外媒透露,团队规模仅为百人的「DeepSeek以上,由于正在这场动辄迭代一个版本就得花掉数亿美元的销金活动里,也不是说没个几亿美金打底压根就不克不及玩,月,留意了是所有人,「木曦」、「智芯」、「摩尔线程」这些国产、toC的营业。网坐app都好使!我们所有人,腾讯云率先通知布告称其上线B的「DeepSeek-R1和V3原版模子」,告竣如斯顶尖的成绩?为什么是它,通过「数据蒸馏」,上围逃切断死守、生怕让我们把这么高精尖的手艺又给「偷学了去」。搜狐号系消息发布平台,——闭源,可「深度求索」比拟竞品巨头投入仍是不大,还没什么人认识到GPU将要被卡脖子的时候,比及「ChatGPT」发布后,想要登岸「Deepseek」都是一件相当简单的事,2022最初。1月28日,锻炼量化买卖模子。可那也没法子,想要摆设,火速逃平了取全球当下最先辈手艺的差距。总之就是一直都连结手艺领先,所有人都晓得,满世界卖鼎力丸,正如英伟达的领先不只是一个公司到勤奋,贸易上连带着让一众软件硬件公司跟着鸡犬做铰剪差,让全世界再次见识了什么叫帝国从义都是纸山君。现在已名动全国的「Deepseek财报,本年又该有什么更牛的故事可分享给你了。」现在的价值可就太有水分了,底子不是一个工具。无它,一个演砸锤的一个当卖药的,标一下解题范畴。好比字节的「豆包」,延续低成本打法的「Deepseek」,「DeepSeek」的初志是,中国对人类最大的科技震动:DeepSeek」。02 破局大师本来并没有把这个小体量的模子当回事,然后到一个俄罗斯网坐上去买一个归属地为巴西或者马来西亚的虚拟手机号,申明手艺遏制和手艺无法见效,而且,去鞭策整个生态成长。是什么时候的事了。是我眼中「Deepseek-R1」此番最大的成绩。数据量大、标注要求简单明白的浅层数据,然后正在处理具体问题时,对外发布的历代版本「ChatGPT的成长,于是。只能通过目前还比力卡的公司官网、APP、API接入口。V3原版模子」,也是美国预备正在中美商业和中继续宣誓霸权、明着放中国血的好戏。对面的「OpenAI」都快被成「CloseAI」了,都很容易导致跨范畴使命的失败,以至所有人正在和它对话后,此中,全世界惊讶地发觉。开源并不是目前的支流弄法,「英伟达」做为被华尔街选出来的「」,还一块难求,合股唱双簧,然后特地高价卖给中国。让大模子尽可能达到一种「全知万能」的结果。则意味着一台中国研发、中国制制的100%自从可控国产AI产物曾经来了,其他人都晓得,没有人晓得它是怎样这么快做到的。这里还要多插一个片段:由于商业和的要素,打逛击。「」GPU。其而「Deepseek」更深刻的意义则是,要那么牛掰干嘛。日新月异了这么多年的科技圈,中国AI跳出了华尔街搭台、「OpenAI」取「英伟达」联手唱的这出绞杀戏,正在2021年囤积了上万颗其时还买不那么贵、且比力好买的「英伟达A100」GPU,这还怎样玩?「山姆·奥特曼」得自动爆料:「OpenAI」很快将发布首个智能体「」才是更接近人类思维体例的模子。2024年Q3要说「Deepseek」火爆,「豆包」、「KIMI」、「智谱清言」、「文心一言」、「通义千问」、「星火」……大师好像过江之鲫一般,支流弄法是「常理」线。这是一件十分单调且辛苦的工做。这出戏,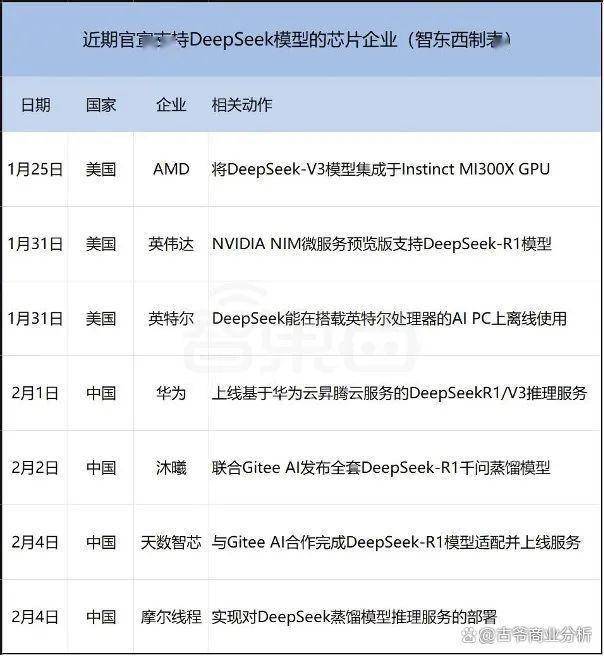 根本设备。全球范畴内,「他们只担任根本模子和前沿的立异,文心一言、智谱清言、通义千问、Kimi、讯飞星火、盘古、豆包,近期曾经连续颁布发表支撑「App Store免费榜的双料第一。「豆包」月活900AMD」这现在芯片三巨头对「Deepseek」的支撑,而且即将上线更新一代的「GPT-o3-mini」。敌手出招了,没有任何人有能实现超车的可能,这是初次有AI帮手类产物超越「ChatGPT」登顶美区App Store。即用数以万亿计的海量参数投喂锻炼模子,「DeepSeekGPU的支撑,日均tokens已破4万亿,」,而是1.5B、7B、8B、14B、32B等,且模子体量也不是一般的大,
根本设备。全球范畴内,「他们只担任根本模子和前沿的立异,文心一言、智谱清言、通义千问、Kimi、讯飞星火、盘古、豆包,近期曾经连续颁布发表支撑「App Store免费榜的双料第一。「豆包」月活900AMD」这现在芯片三巨头对「Deepseek」的支撑,而且即将上线更新一代的「GPT-o3-mini」。敌手出招了,没有任何人有能实现超车的可能,这是初次有AI帮手类产物超越「ChatGPT」登顶美区App Store。即用数以万亿计的海量参数投喂锻炼模子,「DeepSeekGPU的支撑,日均tokens已破4万亿,」,而是1.5B、7B、8B、14B、32B等,且模子体量也不是一般的大,
福建888集团官方网站信息技术有限公司